Wednesday, June 29, 2022
Tuesday, June 28, 2022
HDFS
- hdfs - hadoop distributed file system
- its a distributed file system, data will load in data nodes
https://www.javatpoint.com/hdfs
ls -ltr

ls -ltr -h

or
hadoop fs -ls

Wednesday, June 22, 2022
My SQL
https://www.javatpoint.com/mysql-tutorial
https://www.w3schools.com/mySQl/func_mysql_time_format.asp
mysql> show databases;
mysql> use retail_db;
mysql> show tables like '%pet%';

CREATE TABLE pet
(
name VARCHAR(20),
owner VARCHAR(20),
species VARCHAR(20),
sex CHAR(1),
birth DATE,
death DATE,
id int(20)
);
[haritaraka12078@cxln4 ~]$ cat pet1data.txt
duffball,Diane,hamster,f,1999-03-30,2002-03-30,6\N
hari,manyam,hamster,m,1992-03-30,2004-03-30,2\N
taraka,don,hamster,m,1994-03-30,2007-03-30,3\N
prabhu,teja,hamster,m,1996-03-30,2008-03-30,4\N
manyam,dia,hamster,m,1998-03-30,2003-03-30,5\N
LOAD DATA LOCAL INFILE
'/home/haritaraka12078/pet1data.txt' INTO TABLE pet1
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 ROWS (id, first_name, last_name, email, transactions, @account_creation)
SET account_creation = STR_TO_DATE(@account_creation, '%m/%d/%y');
mysql> LOAD DATA LOCAL INFILE
-> '/home/haritaraka12078/pet1data.txt' INTO TABLE pet
-> FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ;
mysql> insert into pet values('hari','manyam','hamster','m','1992-03-30','2004-03-30','2');
Query OK, 1 row affected (0.02 sec)
mysql> select * from pet;

mysql> select count(8) from pet; -->faster because it will count only the first column
mysql> select count(*) from pet; -->will use the whole table to get to the same result

mysql> select * from pet;
mysql> select name,owner from pet;
mysql> select distinct name from pet;
mysql> select count(distinct name) from pet;
mysql> create table petnew as select * from pet where 1=1; --- > Full Table Create
mysql> create table pet3 as select * from pet where 1=0; --- > Only Table Structure Create
select
birth, CURDATE(),TIMESTAMPDIFF(YEAR,birth,CURDATE()) AS age,
length(name) as length,
rpad(name,15,'*') as rpad,
lpad(name,15,'#') as lpad
from pet;

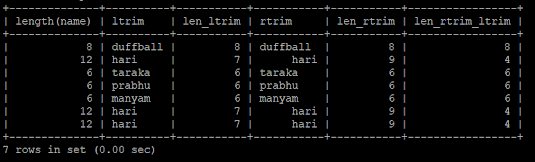
select
length(name),
ltrim(name) as ltrim,
length(ltrim(name)) as len_ltrim,
rtrim(name) as rtrim,
length(rtrim(name)) as len_rtrim,
length(rtrim(ltrim(name))) as len_rtrim_ltrim
from pet;
select
replace(rtrim(ltrim(name)),'h','x') as replace_str,
replace(replace(rtrim(ltrim(name)),'h','x'),'i','y') as mult_replace_str,
replace(name,'l','') as repl,length(replace(name,'l','')) as leng_repl, length(name)-length(replace(name,'l','')) as repeat_string
from pet;

select
repeat(name,2) as repeat_string ,
reverse(name) as rev_String,
concat(owner,'*****',name) as concat_string
from pet;

select
birth,
date_format(birth, '%d-%m-%y') as new_date1,
date_format(birth, '%d%m%y') as new_date2,
DATE_FORMAT(birth, "%M %d %Y") as new_date4,
DATE_FORMAT(birth, "%W %M %e %Y") as new_date5,
ADDDATE(birth, INTERVAL 10 DAY) as add_date,
date_sub(birth, INTERVAL 10 DAY) as sub_date
from pet;

select birth,
day(birth) as day_birth,
dayname(birth) as day_name,
birth+ 1 as new_date3,
CURRENT_DATE() + 1 as cur_date,
CURRENT_TIME() + 1 as cur_time,
CURRENT_TIMESTAMP() + 1 as CUR_TIMESTAMP,
datediff(birth, death) as date_diff
from pet;

SELECT
name,
SUBSTR(name, 5, 3) AS ExtractString ,
substring(name, 5, 3) AS ExtractString1,
SUBSTRING_INDEX("www.w3schools.com", ".", 1) as sub_str1,
SUBSTRING_INDEX("www.w3schools.com", ".", 2) as sub_str2,
SUBSTRING_INDEX("www.w3schools.com", ".", 3) as sub_str3,
SUBSTRING_INDEX("www.w3schools.com", ".", -1) as sub_str5,
SUBSTRING_INDEX("www.w3schools.com", ".", -2) as sub_str6,
SUBSTRING_INDEX(birth, "-", 2) as sub_str4,
instr(birth, "-") as instr1
from pet;

select mail,
instr(mail,'@') as instr1,
instr(mail,'@')+1 as instr2,
substr(mail,instr(mail,'@')+1) as substr1,
substring_index(substr(mail,instr(mail,'@')+1),'.',1) as domain
FROM pet;

select mail,
instr(mail,'@') as instr1,
instr(mail,'@')+1 as instr2,
substr(mail,instr(mail,'@')+1) as substr1,
substring_index(substr(mail,instr(mail,'@')+1),'.',1) as domain,
count(*) as domain_cnt
FROM pet
group by domain
order by domain_cnt desc;

select
mail,
length(mail) as len_mail,
INSTR(mail, '@') as instr1,
length(mail)-INSTR(mail, '@') as instr2,
right ( mail, length(mail)-INSTR(mail, '@') ) as instr3,
substring_index( right ( mail, length(mail)-INSTR(mail, '@') ),'.',1) as domain,
RIGHT(mail, 6) AS right_fun1,
RIGHT(mail, 4) AS right_fun2
from pet;;

====================================================================

Sqoop - My SQL
- Sqoop is used to transfer data from RDBMS (relational database management system) like MySQL and Oracle to HDFS (Hadoop Distributed File System). Big Data Sqoop can also be used to transform data in Hadoop MapReduce and then export it into RDBMS.
- It supports incremental loads of a single table or a free form SQL query as well as saved jobs which can be run multiple times to import updates made to a database since the last import.
- Using Sqoop, Data can be moved into HDFS/hive/hbase from MySQL/ PostgreSQL/Oracle/SQL Server/DB2 and vise versa.
Sqoop Tutorial Link: https://www.javatpoint.com/what-is-sqoop
https://www.tutorialspoint.com/sqoop/index.htm

---------------------------------------------------------------------------------------------------------
--------->> Check Version---------------------------------------------------------------------------------------------------------

-->> Verify : hdfs dfs -cat /user/haritaraka12078/functionscripts/part-m-00003



-->> For Remove HDFS Files
hdfs dfs -rm -r /user/haritaraka12078/functionscripts/sqoop1/*


--------------->> add data to sql table , after that import to hdfs file




With Shell Script

sqoop version
---------------------------------------------------------------------------------------------------------
--------->>List of databases
---------------------------------------------------------------------------------------------------------
sqoop list-databases
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/
--username sqoopuser --password NHkkP876rp
---------------------------------------------------------------------------------------------------------
--------->> Check tables in databases
---------------------------------------------------------------------------------------------------------
sqoop list-tables
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
---------------------------------------------------------------------------------------------------------
--------->> import tables in databases to text file
---------------------------------------------------------------------------------------------------------
sqoop list-tables
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp>retail_db.txt
-->> Verify : cat retail_db.txt
---------------------------------------------------------------------------------------------------------
--------->> import particular table from database to target directory
---------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -split-by EMPLOYEE_ID
--target-dir /user/haritaraka12078/functionscripts
-->> Verify : hdfs dfs -ls /user/haritaraka12078/functionscripts
-->> Verify : hdfs dfs -cat /user/haritaraka12078/functionscripts/part-m-00003
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> import particular table from database to target directory to specific file format-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -split-by EMPLOYEE_ID
-as-textfile
--target-dir /user/haritaraka12078/functionscripts
Note:
(If source column have a primary key then split the column into 4 mappers with total records of a table)
(If source table column does not have a primary key then use the split by column, the table split into 4 mappers based on the column values.)
If a table does not have a primary key defined and the --split-by <col> is not provided, then import will fail unless the number of mappers is explicitly set to one with the --num-mappers 1 option or the --autoreset-to-one-mapper option is used. The option --autoreset-to-one-mapper is typically used with the import-all-tables tool to automatically handle tables without a primary key in a schema.
(If source table column does not have a primary key then use the split by column, the table split into 4 mappers based on the column values.)
If a table does not have a primary key defined and the --split-by <col> is not provided, then import will fail unless the number of mappers is explicitly set to one with the --num-mappers 1 option or the --autoreset-to-one-mapper option is used. The option --autoreset-to-one-mapper is typically used with the import-all-tables tool to automatically handle tables without a primary key in a schema.
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> import All tables
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import-all-tables
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--username sqoopuser --password NHkkP876rp -m 1
-->> Verify :
[haritaraka12078@cxln4 ~]$ hdfs dfs -ls /user/haritaraka12078
[haritaraka12078@cxln4 ~]$ hdfs dfs -ls /user/haritaraka12078/dept
[haritaraka12078@cxln4 ~]$ hdfs dfs -cat /user/haritaraka12078/dept/part-m-00000
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> import ALl Tablees from database to target directory
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import-all-tables
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--username sqoopuser --password NHkkP876rp -m 1
--target-dir /user/haritaraka12078/functionscripts
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> import Particular columns
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -split-by EMPLOYEE_ID
--columns 'EMPLOYEE_ID,PHONE_NUMBER,EMAIL'
--target-dir /user/haritaraka12078/sqoop
-->> Verify :
hdfs dfs -cat /user/haritaraka12078/sqoop/part-m-00003
hdfs dfs -rm -r /user/haritaraka12078/functionscripts/sqoop1/*
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> Fields termination with delimiter
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -split-by EMPLOYEE_ID
--columns 'EMPLOYEE_ID,PHONE_NUMBER,EMAIL'
--target-dir /user/haritaraka12078/functionscripts/sqoop2
--fields-terminated-by '|' --lines-terminated-by '\n'
-->> Verify :
hdfs dfs -cat /user/haritaraka12078/functionscripts/sqoop2/part-m-00003
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> If you want append the data
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees
-split-by EMPLOYEE_ID
--columns 'EMPLOYEE_ID,PHONE_NUMBER,EMAIL'
--target-dir /user/haritaraka12078/functionscripts/sqoop2
--append
--fields-terminated-by '|' --lines-terminated-by '\n'
-----------------------------------------------------------------------------------------------------------------------------------------
--------->> Filter With Where Condition
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -split-by EMPLOYEE_ID
--columns 'EMPLOYEE_ID,PHONE_NUMBER,EMAIL'
--target-dir /user/haritaraka12078/functionscripts/sqoop2 --append
--fields-terminated-by '|' --lines-terminated-by '\n'
--where "EMPLOYEE_ID<185"
EXAMPLE:
mysql> insert into employees values(500,'prabhu','taraka','haritarkaa1',2361236,'2000-12-20','AD_PR',50000.00,0.00,50,90);
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -split-by EMPLOYEE_ID
--columns 'EMPLOYEE_ID,PHONE_NUMBER,EMAIL'
--target-dir /user/haritaraka12078/functionscripts/sqoop2 --append
--fields-terminated-by '|' --lines-terminated-by '\n'
--where "EMPLOYEE_ID=500"
-->> Verify :
hdfs dfs -cat /user/haritaraka12078/functionscripts/sqoop2/* |wc -l
1
hdfs dfs -cat /user/haritaraka12078/functionscripts/sqoop2/*
-----------------------------------------------------------------------------------------------------------------------------------------
--------------->> Add conditions for filtering data
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--query "select EMPLOYEE_ID,PHONE_NUMBER from employees where salary>5000"
--split-by EMPLOYEE_ID --target-dir /user/haritaraka12078/functionscripts/sqoop2
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--query "select EMPLOYEE_ID,PHONE_NUMBER from employees group by job_id where salary>5000 and salary<1000"
--split-by EMPLOYEE_ID --target-dir /user/haritaraka12078/functionscripts/sqoop2
-----------------------------------------------------------------------------------------------------------------------------------------
--------------->> Output on console (EVAL Function)
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop eval
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/retail_db
--username sqoopuser --password NHkkP876rp
--query "select EMPLOYEE_ID,PHONE_NUMBER from employees where EMPLOYEE_ID<105 group by job_id "
-----------------------------------------------------------------------------------------------------------------------------------------
SQOOP JOBS
-----------------------------------------------------------------------------------------------------------------------------------------
- sqoop job --list
- sqoop job --show myjob1
- sqoop job --exec myjob1
- sqoop job --delete myjob1
CREATE JOB IN SQOOP
sqoop job --create myjob1
-- list-tables --connect jdbc:mysql://ip-172-31-13-154/sqoopex
--username sqoopuser --password NHkkP876rp
-----------------------------------------------------------------------------------------------------------------------------------------
MY-SQL TO HIVE
-----------------------------------------------------------------------------------------------------------------------------------------
Table Creation:
sqoop create-hive-table
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--username sqoopuser --password NHkkP876rp
--table employee
--fields-terminated-by '\t' --lines-terminated-by '\n'
--hive-table mysql_employee
Table Creation into HIVE Database:
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--table employee
--username sqoopuser --password NHkkP876rp -m 1
--hive-import --hive-database retail_db
--create-hive-table --hive-table mysql_employee2
--warehouse-dir /user/haritaraka12078/functionscripts/mysql_employee2
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--username sqoopuser --password NHkkP876rp
--table employee
-split-by employee_id
--fields-terminated-by '\t' --lines-terminated-by '\n' -m 1
--hive-import --hive-database retail_db
--create-hive-table --hive-table mysql_employee2
--warehouse-dir /user/haritaraka12078/functionscripts/mysql_employee3
overwrite
----------------------
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--username sqoopuser --password NHkkP876rp
--table employee -split-by employee_id
--fields-terminated-by '\t' --lines-terminated-by '\n' -m 1
--hive-import --hive-database retail_db
--create-hive-table --hive-table mysql_employee2
---hive-overwrite
-warehouse-dir /user/haritaraka12078/functionscripts/mysql_employee3
partition-key
----------------------
date=`date "+%m/%d/%y"
`
sqoop import
--connect jdbc:mysql://cxln2.c.thelab-240901.internal/sqoopex
--username sqoopuser --password NHkkP876rp
--table employee -split-by employee_id
--fields-terminated-by '\t' --lines-terminated-by '\n' -m 1
--hive-import --hive-table mysql_employee2
--warehouse-dir /user/haritaraka12078/functionscripts/mysql_employee3
--hive-partition-key dt --hive-partition-value $date
-----------------------------------------------------------------------------------------------------------------------------------------
Sqoop Incremental Operations
-----------------------------------------------------------------------------------------------------------------------------------------
from mysql to hdfs. the table rdBms columns should be in sorted order(asc).
day0 10000 files
day1 1000 files
no need to load again day0 files.. for this purpose we are using incremental operations
sqoop import
--connect jdbc:mysql://ip-172-31-13-154/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -m 1
--target-dir /user/haritaraka12078/functionscripts/sqoop2
--incremental append
--check-column EMPLOYEE_ID
--last-value 0
verify : hdfs dfs -cat /user/haritaraka12078/functionscripts/sqoop2/part-00000 -----> 6 records
Now Insert extra records in mysql table....------> 2 records
verify : hdfs dfs -cat /user/haritaraka12078/functionscripts/sqoop2/part-00001--------> 6+2 = 8 records
create the job for incremental
------------------------------------
sqoop job --create incrementa20
--connect jdbc:mysql://ip-172-31-13-154/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -m 1
--target-dir /user/haritaraka12078/functionscripts/sqoop2
--incremental append
--check-column EMPLOYEE_ID
--last-value 0
-----------------------------------------------------------------------------------------------------------------------------------------
To store the file in HDFS as a sequential format.
-----------------------------------------------------------------------------------------------------------------------------------------
if data import from sql to hdfs in sequential format, it will be in encrypted file. we can't able to read the data
sqoop import
--connect jdbc:mysql://ip-172-31-13-154/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -m 1
--split-by EMPLOYEE_ID
--fields-terminated-by '\t' --lines-terminated-by '\n' --as-sequencefile
--target-dir /user/haritaraka12078/functionscripts/sqoop2
-----------------------------------------------------------------------------------------------------------------------------------------
To store the file in HDFS as a AVRO format.
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop import
--connect jdbc:mysql://ip-172-31-13-154/retail_db
--username sqoopuser --password NHkkP876rp
--table employees -m 1
--split-by EMPLOYEE_ID
--fields-terminated-by '\t' --lines-terminated-by '\n' --as-avrodatafile
--target-dir /user/haritaraka12078/functionscripts/sqoop2
- Avro format is a row-based storage format for Hadoop, which is widely used as a serialization platform.
- Avro format stores the schema in JSON format, making it easy to read and interpret by any program.
- The data itself is stored in a binary format making it compact and efficient in Avro files
Below is a basic sample file of Avro schema.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | { "type": "record", "name": "thecodebuzz_schema", "namespace": "thecodebuzz.avro", "fields": [ { "name": "username", "type": "string", "doc": "Name of the user account on Thecodebuzz.com" }, { "name": "email", "type": "string", "doc": "The email of the user logging message on the blog" }, { "name": "timestamp", "type": "long", "doc": "time in seconds" } ], "doc:": "A basic schema for storing thecodebuzz blogs messages"} |
create the hive table with avro format using below query
CREATE EXTERNAL TABLE departments_avro
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION '/user/haritaraka12078/functionscripts/sqoop2 '
TBLPROPERTIES ('avro.schema.url'='/user/venkatateju19854978/schema/employee.avsc');
-----------------------------------------------------------------------------------------------------------------------------------------
UPDATE
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop eval
--connect jdbc:mysql://ip-172-31-13-154/retail_db_13072017
--username sqoopuser --password NHkkP876rp
--query "update departments set department_name='Testing Merge1' where department_id = 60000"
-----------------------------------------------------------------------------------------------------------------------------------------
INSERT
-----------------------------------------------------------------------------------------------------------------------------------------
sqoop eval --connect jdbc:mysql://ip-172-31-13-154/retail_db_13072017
--username sqoopuser --password NHkkP876rp
--query "insert into departments values (60000, 'Inserting for merge')"
-----------------------------------------------------------------------------------------------------------------------------------------
EXPORT
-----------------------------------------------------------------------------------------------------------------------------------------
Export data from HDFS to mysql
Before we import ,we need to have the same
schema/table in the destination location in this scenario in mysql
sqoop export
--connect jdbc:mysql://ip-172-31-13-154/retail_db
--username sqoopuser --password NHkkP876rp
--table venkat_customer
--export-dir /user/venkatateju19854978/mysql-tables/customers6
--input-fields-terminated-by ',' --input-lines-terminated-by '\n'
--connect jdbc:mysql://ip-172-31-13-154/retail_db
--username sqoopuser --password NHkkP876rp
--table venkat_customer
--export-dir /user/venkatateju19854978/mysql-tables/customers6
--input-fields-terminated-by ',' --input-lines-terminated-by '\n'
Commands List:
sqoop import-all-tables jdbc/database>myfile.txt
top 10 tables
 |
With Shell Script
Subscribe to:
Comments (Atom)