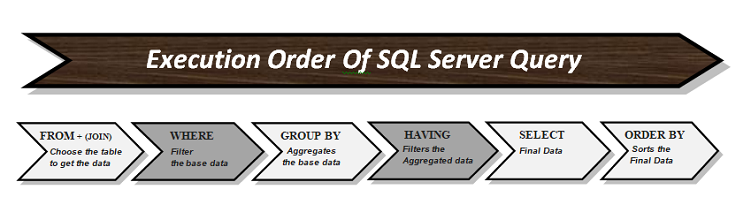
Explain Order of Execution of SQL Queries
- FROM – Identifies the source tables.
- JOIN – Combines multiple tables.
- WHERE – Filters rows before grouping.
- GROUP BY – Groups data.
- HAVING – Filters groups.
- SELECT – Chooses columns.
- ORDER BY – Sorts results.
- LIMIT/OFFSET – Limits output.
SELECT deparment_id,COUNT(*)
FROM emp1
WHERE salary > 100
GROUP BY deparment_id
HAVING COUNT(*) > 1
ORDER BY deparment_id ASC
FETCH FIRST 1 ROWS ONLY;
NOte: In Oracle SQL, the LIMIT clause (as in MySQL) is not available.
===============================================================================
2) What is the Difference Between WHERE and HAVING?
WHERE: Filters records before grouping.
HAVING: Filters records after grouping.
SELECT deparment_id,COUNT(*)
FROM emp1
WHERE salary > 100 --- applied before grouping
GROUP BY deparment_id
HAVING COUNT(*) > 1 --- applied after grouping
ORDER BY deparment_id ASC
FETCH FIRST 1 ROWS ONLY;
===============================================================================
3) What is the Use of GROUP BY?
GROUP BY is used to aggregate data based on a column.
SELECT dept_id, COUNT(*) AS count_dept_id FROM emp1
GROUP BY dept_id;
===============================================================================
To rename a column in an Oracle SQL table?
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name;
ALTER TABLE emp1 rename COLUMN deparment_id to dept_id;
You cannot rename multiple columns in a single ALTER TABLE statement.
Ensure that no dependent views, triggers, or procedures rely on the old column name. If they do, you may need to update them.
===============================================================================
4) Explain All Types of Joins in SQL
- INNER JOIN: Returns matching records from both tables.
- LEFT JOIN: Returns all records from the left table and matching records from the right table.
- RIGHT JOIN: Returns all records from the right table and matching records from the left table.
- FULL JOIN: Returns all records from both tables when there is a match.
SELECT employees.name, department.dept_name
FROM employees
INNER JOIN department ON employees.dept_id = department.dept_id;
===============================================================================
5) What Are Triggers in SQL?
- A trigger in Oracle SQL is a stored procedure that automatically executes before or after a specific event on a table, such as INSERT, UPDATE, or DELETE.
- Triggers are useful for enforcing business rules, maintaining data integrity, and automating system tasks without requiring explicit calls from applications.
CREATE OR REPLACE TRIGGER trigger_name
BEFORE | AFTER | INSTEAD OF
INSERT | UPDATE | DELETE
ON table_name
FOR EACH ROW
BEGIN
-- Trigger logic here
END;
/
CREATE OR REPLACE TRIGGER log_employee_updates
AFTER UPDATE ON employees
FOR EACH ROW
BEGIN
INSERT INTO employee_log (employee_id, old_salary, new_salary, change_date)
VALUES (:OLD.employee_id, :OLD.salary, :NEW.salary, SYSDATE);
END;
In this example, the trigger log_employee_updates captures the old and new salary of an employee whenever their record is updated, logging this information into the employee_log table. This ensures that all changes are tracked efficiently, enhancing data management and accountability within the database.
----------------
CREATE OR REPLACE TRIGGER trg_uppercase
BEFORE INSERT OR UPDATE ON emp1
FOR EACH ROW
BEGIN
:NEW.first_name := LOWER(:NEW.first_name);
:NEW.last_name := LOWER(:NEW.last_name);
END;
/
UPDATE emp1 SET first_name = UPPER(first_name), last_name = UPPER(last_name);
divya rani
prabhu tarak
sunny bunny
===============================================================================
Use a Trigger to Ensure Uppercase Data (Automatic Conversion)?
To automatically convert inserted or updated values to uppercase, create a BEFORE INSERT/UPDATE trigger:
CREATE OR REPLACE TRIGGER trg_uppercase
BEFORE INSERT OR UPDATE ON emp1
FOR EACH ROW
BEGIN
:NEW.first_name := UPPER(:NEW.first_name);
:NEW.last_name := UPPER(:NEW.last_name);
END;
/
UPDATE emp1 SET first_name = UPPER(first_name), last_name = UPPER(last_name);
DIVYA RANI
PRABHU TARAK
SUNNY BUNNY
insert into emp1 values(111, 'divya','rani');
111 DIVYA RANI
===============================================================================
how to check trigger details?
SELECT trigger_name FROM user_triggers WHERE trigger_name = 'TRG_UPPERCASE';
===============================================================================
how to drop or disable triggers?
DROP TRIGGER TRG_UPPERCASE;
===============================================================================
Convert all column values to UPPER Case?
UPDATE emp1 SET first_name = UPPER(first_name), last_name = UPPER(last_name);
===============================================================================
Creating a Trigger to Update Salary in Oracle SQL?
CREATE OR REPLACE TRIGGER trg_update_salary
BEFORE UPDATE ON emp1
FOR EACH ROW
BEGIN
-- Restrict salary increase to 20%
IF :NEW.salary > :OLD.salary * 1.2 THEN
RAISE_APPLICATION_ERROR(-20001, 'Salary increase cannot exceed 20%');
END IF;
END;
/
select salary from emp1 where emp_id=133; ---->> 0.12
update emp1 set salary=22.23 where emp_id=133;
Error report -
ORA-20001: Salary increase cannot exceed 20%
ORA-06512: at "C##PRABHU.TRG_UPDATE_SALARY", line 4
ORA-04088: error during execution of trigger 'C##PRABHU.TRG_UPDATE_SALARY'
update emp1 set salary=0.02 where emp_id=133; ---->> 0.02
-------->> Trigger to Track Salary Updates in a Log Table
CREATE TABLE employee_salary_log (
log_id NUMBER GENERATED ALWAYS AS IDENTITY,
emp_id NUMBER,
old_salary NUMBER,
new_salary NUMBER,
updated_by VARCHAR2(50),
update_time TIMESTAMP DEFAULT SYSTIMESTAMP
);
CREATE OR REPLACE TRIGGER trg_salary_update_log
AFTER UPDATE OF salary ON emp1
FOR EACH ROW
BEGIN
INSERT INTO employee_salary_log (emp_id, old_salary, new_salary, updated_by)
VALUES (:OLD.emp_id, :OLD.salary, :NEW.salary, USER);
END;
/
UPDATE emp1 SET salary = salary * 1.1 WHERE emp_id = 111;
UPDATE emp1 SET salary = salary * 1.1 WHERE emp_id=433;
SELECT * FROM employee_salary_log;
3 111 2334.56 2568.02 C##PRABHU 22-03-25 2:00:38.420000000 PM
7 433 11.56 12.72 C##PRABHU 22-03-25 2:05:07.737000000 PM
drop trigger trg_salary_update_log;
drop trigger trg_update_salary;
===============================================================================
7) Explain All Types of Window Functions
Window functions operate over a set of rows related to the current row.
1) RANK() – Assigns a rank to each row with gaps in ranking.
SELECT first_name, dept_id, salary,
RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS ranking
FROM emp1 where salary<500;
PRABHU 10 22.23 1
divya 10 11.56 2
divya 10 11.56 2
divya 10 0 4
SANDEEP 20 34.56 1
2) DENSE_RANK() – Assigns consecutive ranks without gaps.
SELECT first_name, dept_id, salary,
DENSE_RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS ranking
FROM emp1 where salary<500;
PRABHU 10 22.23 1
divya 10 11.56 2
divya 10 11.56 2
divya 10 0 3
SANDEEP 20 34.56 1
3) ROW_NUMBER() – Assigns a unique row number to each row.
SELECT first_name, dept_id, salary,
row_number() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS row_num
FROM emp1 where salary<500;
PRABHU 10 22.23 1
divya 10 11.56 2
divya 10 11.56 3
divya 10 0 4
SANDEEP 20 34.56 1
4) LEAD() – Retrieves the next row’s value.
select first_name,dept_id, salary from emp1 where salary<500 order by salary desc;
SANDEEP 20 34.56
PRABHU 10 22.23
divya 10 11.56
divya 10 11.56
divya 10 0
SELECT first_name,dept_id, salary,
LEAD(salary) OVER (ORDER BY salary DESC) AS next_salary
FROM emp1 where salary<500;
SANDEEP 20 34.56 22.23
PRABHU 10 22.23 11.56
divya 10 11.56 11.56
divya 10 11.56 0
divya 10 0 (null)
5) LAG() – Retrieves the previous row’s value.
SELECT first_name,dept_id, salary,
LAG(salary) OVER (ORDER BY salary DESC) AS previous_salary
FROM emp1 where salary<500;
SANDEEP 20 34.56 (null)
PRABHU 10 22.23 34.56
divya 10 11.56 22.23
divya 10 11.56 11.56
divya 10 0 11.56
===============================================================================
What is the Difference Between DML, DDL, and DCL?
DML (Data Manipulation Language):
- Used for managing data within schema objects.
- Operations include SELECT, INSERT, UPDATE, and DELETE.
- These operations affect the data stored in the tables but do not change the structure of the database.
INSERT INTO emp1 (emp_id, first_name, salary) VALUES (101, 'John Doe', 50000.1);
DDL (Data Definition Language):
- Used for defining and modifying database structures like tables, schemas, indexes, and views.
- Operations include CREATE, ALTER, DROP, TRUNCATE, and RENAME.
- DDL changes the database schema and structure.
CREATE TABLE emp2 (employee_id INT, name VARCHAR(100), salary DECIMAL);
ALTER TABLE emp2 ADD pincode INT;
DCL (Data Control Language):
- Used to control access to data within the database.
- Operations include GRANT (to give privileges) and REVOKE (to remove privileges).
GRANT SELECT, INSERT ON emp1_sample TO c##prabhu;
REVOKE DELETE ON emp1 FROM c##prabhu;
===============================================================================
Rename Table Name ?
ALTER TABLE old_table_name RENAME TO new_table_name;
ALTER TABLE sample_emp_2 RENAME TO emp3;
===============================================================================
Creating a Table Identical to Another Table?
CREATE TABLE new_emp2 AS SELECT * FROM emp1 WHERE 1=1; -->> Data + STRUCTURE
CREATE TABLE new_emp2 AS SELECT * FROM emp1 WHERE 1=0; -->>Only STRUCTURE
===============================================================================
What is the Difference Between DELETE and TRUNCATE?
DELETE:
- Removes rows one by one and logs each row deletion.
- Can be rolled back if inside a transaction (transactional).
- Allows using a WHERE clause to delete specific records.
- Slower than TRUNCATE due to row-by-row logging.
TRUNCATE:
- Removes all rows from a table without logging individual row deletions.
- Faster than DELETE because it does not log individual row deletions and does not generate triggers.
- Cannot be rolled back once committed (non-transactional in most databases).
- Does not fire triggers or check constraints.
- Does not allow a WHERE clause (removes all rows).
DROP
- The DROP statement is used to completely remove a database object, such as a table, view, index, or schema, from the database.
- It is faster than both DELETE and TRUNCATE because it removes the entire table and all associated data and schema.
- Cannot be rolled back (once executed, the table and its data are permanently removed).
- Use when you want to permanently delete a table or database object.
- delete from new_emp2 where salary is null; -->>Delete salary null rows
- truncate table new_emp2; --->> delete all rows in table
- drop table new_emp2; --->> Delete complete table
===============================================================================
What are Aggregate Functions and When Do We Use Them?
- Aggregate functions are SQL functions that operate on multiple rows of a table or a group of rows, and return a single value as a result.
- They are often used with the GROUP BY clause to perform calculations on groups of data.
SELECT dept_id, COUNT(*) AS count_deptid FROM emp1 GROUP BY dept_id;
SELECT dept_id, sum(salary) AS sum_salary FROM emp1 GROUP BY dept_id;
SELECT dept_id, max(salary) AS sum_salary FROM emp1 GROUP BY dept_id;
SELECT dept_id, min(salary) AS sum_salary FROM emp1 GROUP BY dept_id;
SELECT dept_id, avg(salary) AS sum_salary FROM emp1 GROUP BY dept_id;
===============================================================================
Which is faster between CTE and Subquery?
CTE (Common Table Expression):--->>
- CTEs are temporary result sets defined within the execution scope of a SELECT, INSERT, UPDATE, or DELETE statement.
- They improve query readability and can be referenced multiple times within the query.
- CTEs are especially useful in recursive queries or when the same result needs to be reused in multiple places within the query.
with avg_salarytable as
(
SELECT dept_id, avg(salary) AS avg_salary FROM emp1 GROUP BY dept_id
)
SELECT dept_id, avg_salary from avg_salarytable;
===============================================================================
Difference between Primary Key and Secondary Key and Foreign Key?
- Primary Key (PK): Ensures each record is uniquely identified.
- Secondary Key (SK): Used for indexing and faster searches.
- Foreign Key (FK): Establishes relationships between tables.
1. Primary Key (PK)
- A Primary Key is a column (or a combination of columns) that uniquely identifies each row in a table.
- Ensures uniqueness of records.
- Cannot contain NULL values.
- Only one primary key per table.
- Automatically indexed for faster lookups.
Often used as a reference by foreign keys in other tables.
2. Secondary Key (SK)
- A Secondary Key is a column (or set of columns) used for indexing and searching but does not necessarily enforce uniqueness. It improves query performance.
- Used for indexing and improving search speed.
- Can contain duplicate values (not necessarily unique).
- Can have NULL values.
- A table can have multiple secondary keys.
- Not used for establishing relationships like foreign keys.
3. Foreign Key (FK)
- A Foreign Key is a column (or a set of columns) in one table that references the Primary Key of another table to establish a relationship between tables.
- Enforces referential integrity (ensures valid relationships between tables).
- Can contain duplicate values (many employees can belong to the same department).
- Can contain NULL values (if not all employees belong to a department).
- A table can have multiple foreign keys, each referencing different tables.
CREATE TABLE sampEmp (
EmployeeID INT PRIMARY KEY, -- EmployeeID uniquely identifies each employee
Name VARCHAR(100),
Department VARCHAR(50)
);
CREATE TABLE sampEmp_FK (
ID INT PRIMARY KEY,
Name VARCHAR(100),
EmployeeID INT,
FOREIGN KEY (EmployeeID) REFERENCES sampEmp(EmployeeID) -- Foreign Key Relationship
);
CREATE INDEX idx_department ON sampEmp(Department);
===============================================================================
Find the second highest salary of an employee?
ROW_NUMBER() assigns a row number to each unique salary.
SELECT salary FROM (
SELECT salary, ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num
FROM (SELECT DISTINCT salary FROM emp1) t
) ranked_salaries
WHERE row_num = 2;
DENSE_RANK() assigns a unique rank without skipping numbers, even if salaries are duplicated.
select salary, rank from (
select salary, dense_rank()OVER (order by salary desc) as rank
from (SELECT DISTINCT salary FROM emp1) t
)ranked_salaries
where rank=2;
The inner query finds the highest salary. The outer query gets the maximum salary less than the highest, effectively giving the second highest.
SELECT MAX(salary) AS second_highest_salary
FROM emp1
WHERE salary < (SELECT MAX(salary) FROM emp1);
===============================================================================
Difference Between UNION and UNION ALL in SQL
select * from emp1 where salary<1500 --->> 6 rows fetch
union
select * from emp4 where salary<1500;
select * from emp1 where salary<1500 --->> 12 rows fetch
union all
select * from emp4 where salary<1500;
===============================================================================
Different types of Operators?
---Arithmetic Operators
- select salary, salary+100 from emp1;
- select salary, salary-100 from emp1;
- select salary, salary*100 from emp1;
- select salary, salary/100 from emp1;
- select salary, salary %3 from emp1;
---Comparison Operators
- SELECT * FROM emp1 WHERE salary = 50000;
- SELECT * FROM emp1 WHERE salary != 50000;
- SELECT * FROM emp1 WHERE salary > 50000;
- SELECT * FROM emp1 WHERE salary < 50000;
- SELECT * FROM emp1 WHERE salary >= 50000;
- SELECT * FROM emp1 WHERE salary <= 50000;
---Logical Operators
- SELECT * FROM employees WHERE salary > 40000 AND department = 'IT';
- SELECT * FROM employees WHERE salary > 60000 OR department = 'HR';
- SELECT * FROM employees WHERE NOT department = 'Sales';
---String Operators
- select first_name, first_name || 'HARI' as concat_fn from emp1;
- select first_name, last_name, concat (first_name, last_name) as full_name from emp1;
---Special Operators
- select * from emp1 where salary between 1000 AND 5000;
- select * from emp1 where first_name in ('DIVYA', 'SUNNY');
- select * from emp1 where city like 'vijay%';
- select * from emp1 where last_name is null;
---Set Operators
- select * from emp1 union select * from emp4;
- select * from emp1 union all select * from emp4;
===============================================================================
Difference Between GROUP BY and WHERE in SQL?
SELECT dept_id, COUNT(*) AS total_employees FROM emp1
WHERE salary > 50000
GROUP BY department;
===============================================================================
When to Use HAVING Instead of WHERE?
- WHERE filters before grouping.
- HAVING filters after GROUP BY (on aggregated results).
SELECT department, SUM(salary) AS total_salary
FROM employees
GROUP BY department
HAVING SUM(salary) > 200000;
Groups by department. Filters departments after grouping (SUM(salary) > 200000).
===============================================================================
Difference Between WHERE and HAVING in SQL
SELECT emp_id, emp_name, salary FROM Employees WHERE salary > 50000;
SELECT department, SUM(salary) AS total_salary FROM Employees
GROUP BY department
HAVING SUM(salary) > 100000;
===============================================================================
Difference between CHAR and NCHAR in Oracle SQL
CREATE TABLE char_test (name CHAR(10));
INSERT INTO char_test VALUES ('Hello');
SELECT LENGTH(name), DUMP(name) FROM char_test;
--->Even though "Hello" is 5 characters, it will store 10 characters (adding spaces).
CREATE TABLE nchar_test (name NCHAR(10));
INSERT INTO nchar_test VALUES (N'你好世界'); -- Chinese characters
SELECT LENGTH(name), DUMP(name) FROM nchar_test;
--->Stores Unicode data, useful for multilingual applications.
===============================================================================
Difference Between VARCHAR and NVARCHAR in Oracle SQL
CREATE TABLE test_varchar (name VARCHAR2(10));
INSERT INTO test_varchar VALUES ('Hello');
SELECT name, LENGTH(name) FROM test_varchar;
--->Stores up to 10 bytes, depending on character encoding.
CREATE TABLE test_nvarchar (name NVARCHAR2(10));
INSERT INTO test_nvarchar VALUES (N'你好世界'); -- Chinese characters
SELECT name, LENGTH(name) FROM test_nvarchar;
--->Stores up to 10 Unicode characters, ideal for multilingual data.
===============================================================================
What are Constraints?
- Constraints in SQL are rules applied to columns in a table to ensure data integrity, accuracy, and consistency.
- They restrict invalid data from being inserted into the database.
===============================================================================
Differences Between SQL Constraints
===============================================================================
Key Differences NOT NULL vs UNIQUE
- NOT NULL: Ensures a column cannot have NULL values.
- UNIQUE: Ensures no duplicate values, but can allow NULL values.
Example: A column with UNIQUE can have multiple NULL values.
CREATE TABLE Employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR2(100) NOT NULL,
salary NUMBER
);
insert into Employees(emp_id, salary) values (100,1000);
--Error report -
--ORA-01400: cannot insert NULL into ("C##PRABHU"."EMPLOYEES"."EMP_NAME")
CREATE TABLE Employees_unique (
emp_id INT PRIMARY KEY,
email VARCHAR2(100) UNIQUE
);
insert into Employees_unique(emp_id, email) values (100,'abc@gmail.com');
insert into Employees_unique(emp_id, email) values (1200,'abc@gmail.com');
--Error report -
--ORA-00001: unique constraint (C##PRABHU.SYS_C007541) violated
===============================================================================
Key Differences PRIMARY KEY vs UNIQUE
- PRIMARY KEY = UNIQUE + NOT NULL.
- UNIQUE allows NULL values, PRIMARY KEY does not.
- A table can have multiple UNIQUE constraints but only one PRIMARY KEY.
CREATE TABLE Employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR2(100) NOT NULL
);
===============================================================================
Key Differences PRIMARY KEY vs FOREIGN KEY
- PRIMARY KEY: Identifies a record uniquely.
- FOREIGN KEY: Creates a link between tables, referencing a PRIMARY KEY or UNIQUE column in another table.
CREATE TABLE Dept_PK (
dept_id INT PRIMARY KEY,
dept_name VARCHAR2(100)
);
CREATE TABLE Dept_FK (
emp_id INT PRIMARY KEY,
emp_name VARCHAR2(100),
dept_id INT,
CONSTRAINT fk_dept FOREIGN KEY (dept_id) REFERENCES Dept_PK(dept_id));
===============================================================================
Key Differences CHECK vs DEFAULT
- CHECK: Restricts values based on a condition (e.g., age > 18).
- DEFAULT: Provides a default value when no value is provided.
CREATE TABLE Employees_check (
emp_id INT PRIMARY KEY,
emp_name VARCHAR2(100),
salary NUMBER CHECK (salary > 30000)
);
insert into Employees_check (emp_id, salary) values (100,1000);
--Error report -
--ORA-02290: check constraint (C##PRABHU.SYS_C007545) violated
--The salary must be greater than 30,000.
CREATE TABLE Employees_default (
emp_id INT PRIMARY KEY,
emp_name VARCHAR2(100),
join_date DATE DEFAULT SYSDATE
);
insert into Employees_default (emp_id, emp_name) values (100,'Prahbu');
--1 row inserted.
--If join_date is not provided, the system date will be used.
--100 Prahbu 24-03-25
===============================================================================
different types of keys in SQL with examples:
---------------------------------
1. Primary Key
---------------------------------
Definition: A primary key uniquely identifies each record in a table. A table can have only one primary key, and the values in the primary key columns must be unique and not NULL.
Example ---- >> StudentID is the primary key and will uniquely identify each student.
CREATE TABLE Student (
StudentID INT PRIMARY KEY, Name VARCHAR(100), Age INT);
---------------------------------
2. Foreign Key
---------------------------------
Definition: A foreign key is a column (or combination of columns) in a table that links to the primary key of another table. It ensures referential integrity between the two tables.
Example ---- >> CustomerID in the Order table is a foreign key that references the CustomerID in the Customer table.
CREATE TABLE Order (
OrderID INT PRIMARY KEY, CustomerID INT, OrderDate DATE, FOREIGN KEY (CustomerID) REFERENCES Customer(CustomerID));
---------------------------------
3. Unique Key
---------------------------------
Definition: A unique key ensures that all values in a column (or a combination of columns) are unique across the table, but unlike the primary key, it can allow NULL values (only one NULL value is allowed).
Example ---- >> Email has a unique constraint, ensuring that no two users can have the same email address.
CREATE TABLE User ( UserID INT PRIMARY KEY, Email VARCHAR(100) UNIQUE, Name VARCHAR(100));
---------------------------------
4. Composite Key
---------------------------------
Definition: A composite key is a primary key that consists of two or more columns in a table. This is used when a single column is not enough to uniquely identify records.
Example ---- >> the combination of OrderID and ProductID forms a composite primary key to uniquely identify each order detail.
CREATE TABLE OrderDetails ( OrderID INT, ProductID INT, Quantity INT, PRIMARY KEY (OrderID, ProductID));
---------------------------------
5. Candidate Key
---------------------------------
Definition: A candidate key is a set of one or more columns that could be used as a primary key. A table can have multiple candidate keys, and one is chosen as the primary key.
Example ---- >> both SSN and Email are candidate keys because they could uniquely identify each employee. The EmployeeID is selected as the primary key.
CREATE TABLE Employee ( EmployeeID INT PRIMARY KEY,
SSN VARCHAR(11) UNIQUE, -- Candidate Key
Email VARCHAR(100) UNIQUE -- Candidate Key
);
---------------------------------
6. Alternate Key
---------------------------------
Definition: An alternate key is a candidate key that was not chosen as the primary key.
Example ---- >> Email is an alternate key, as it is a candidate key but not chosen as the primary key (the primary key is CustomerID).
CREATE TABLE Customer (
CustomerID INT PRIMARY KEY,
Email VARCHAR(100) UNIQUE -- Alternate Key
);
---------------------------------
7. Super Key
---------------------------------
Definition: A super key is a set of one or more columns that can uniquely identify a record in a table. Every primary key is a super key, but a super key can have extra attributes.
Example ---- >> super key could be {ProductID, ProductCode}, but ProductID alone is sufficient as the primary key.
CREATE TABLE Product (
ProductID INT,
ProductCode VARCHAR(50),
ProductName VARCHAR(100),
PRIMARY KEY (ProductID)
);
---------------------------------
8. Natural Key
---------------------------------
Definition: A natural key is a key that is formed from data that already exists in the real world and has inherent meaning.
Example ---- >> CountryCode is a natural key because it naturally exists in the real world and uniquely identifies each country.
CREATE TABLE Country (
CountryCode CHAR(2) PRIMARY KEY,
CountryName VARCHAR(100)
);
---------------------------------
9. Surrogate Key
---------------------------------
Definition: A surrogate key is an artificial key created to uniquely identify records when no natural key exists. It has no inherent meaning outside the database.
Example ---- >> EmployeeID is a surrogate key because it is automatically generated and does not have any real-world meaning.
CREATE TABLE Employee (
EmployeeID INT PRIMARY KEY AUTO_INCREMENT,
Name VARCHAR(100),
Position VARCHAR(50)
);
===============================================================================
What is an Index in SQL?
An index in SQL is a database object that improves the speed of data retrieval operations on a table. It is similar to an index in a book, which allows you to quickly locate information without scanning every page.
Oracle uses a mechanism called "Index Organized Tables" (IOT) to achieve similar functionality. An IOT stores the table data in the index structure itself, which can improve performance for certain queries.
Indexes do not affect the actual data but improve query performance. However, they may slow down INSERT, UPDATE, and DELETE operations because the index must also be updated when data changes.
CREATE TABLE employees5 (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
department_id NUMBER
) ORGANIZATION INDEX;
CREATE INDEX idx_department ON employees5(department_id);
===============================================================================
Differences of Keys & Constraints?:
Keys are used to identify records uniquely or to create relationships between tables.
Constraints are rules that enforce data integrity, ensuring that the data stored in a table meets certain criteria. Constraints can define keys (like primary and foreign keys), but they also cover a broader range of rules such as uniqueness, non-nullability, and valid data checks.
===============================================================================
Types of Indexes in SQL?
Clustered Index (SQL Server & MySQL)
- Sorts and stores data physically in the table based on key values (only one per table).
- Used for primary keys to optimize data retrieval.
NON-CLUSTERED INDEX
- Creates a separate structure that stores only the index and a pointer to the actual data. (A table can have multiple non-clustered indexes).
- Used for fast searching on columns that are frequently used in WHERE clauses.
CREATE TABLE employees6 (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
department_id NUMBER,
phoneno VARCHAR(255),
email VARCHAR(255)
);
CREATE INDEX idx_phone ON employees6(phoneno);
UNIQUE INDEX
- Ensures that all values in the column(s) are unique (automatically created for PRIMARY KEY and UNIQUE constraints).
- Used when you need unique values (e.g., email, username).
CREATE TABLE employees6 (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
department_id NUMBER
);
CREATE UNIQUE INDEX idx_unique_last_name ON employees6 (last_name);
select * from USER_INDEXES WHERE table_name='EMPLOYEES6';
--SYS_C007549
--IDX_UNIQUE_LAST_NAME
FULL-TEXT INDEX (SQL SERVER)
- Enables fast text searches on large textual data (works with CONTAINS() and FREETEXT() functions).
- Used for search operations in large text-based columns (e.g., article content, product descriptions).
CREATE FULLTEXT INDEX ON Articles(content);
COMPOSITE INDEX
- An index created on multiple columns together.
- Used when queries filter by multiple columns frequently.
CREATE TABLE employees6 (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
department_id NUMBER
);
CREATE INDEX idx_composite ON employees6(first_name, department_id);
select * from USER_INDEXES WHERE table_name='EMPLOYEES6';
---SYS_C007549
---IDX_UNIQUE_LAST_NAME
---IDX_COMPOSITE
FILTERED INDEX (SQL SERVER)
- Applies an index to only a subset of data (e.g., indexing only active users).
- Improves performance when querying a subset of data
CREATE INDEX idx_active_users ON Users(status) WHERE status = 'active';
BITMAP INDEX (ORACLE, POSTGRESQL)
- Uses a bitmap (0s and 1s) instead of a traditional B-tree structure for indexing.
- Used in low-cardinality columns (e.g., gender, status flags).
CREATE BITMAP INDEX idx_email ON employees6(email);
===============================================================================
How to check Index details for the table?
select index_name, index_type, uniqueness, constraint_index from USER_INDEXES WHERE table_name='EMPLOYEES6';
---------------------------------------------------------------------------------
INDEX_NAME INDEX_TYPE UNIQUENESS CONSTRAINT_INDEX
---------------------------------------------------------------------------------
SYS_C007549 NORMAL UNIQUE YES
IDX_UNIQUE_LAST_NAME NORMAL UNIQUE NO
IDX_COMPOSITE NORMAL NONUNIQUE NO
IDX_EMAIL BITMAP NONUNIQUE NO
IDX_PHONE NORMAL NONUNIQUE NO
SELECT index_name, column_name, column_position FROM user_ind_columns WHERE table_name='EMPLOYEES6';
---------------------------------------------------------------------------------
INDEX_NAME column_name column_position
---------------------------------------------------------------------------------
SYS_C007549 EMPLOYEE_ID 1
IDX_UNIQUE_LAST_NAME LAST_NAME 1
IDX_COMPOSITE FIRST_NAME 1
IDX_COMPOSITE DEPARTMENT_ID 2
IDX_EMAIL EMAIL 1
IDX_PHONE PHONENO 1
===============================================================================
How to Drop Index details for the table?
DROP INDEX IDX_PHONE;
===============================================================================
removing all indexes associated with a specific table in an Oracle database.?
BEGIN
FOR idx IN (SELECT index_name FROM user_indexes WHERE table_name = 'EMPLOYEES6') LOOP
EXECUTE IMMEDIATE 'DROP INDEX ' || idx.index_name;
END LOOP;
END;
/
--02429. 00000 - "cannot drop index used for enforcement of unique/primary key"
--*Cause: user attempted to drop an index that is being used as the
-- -enforcement mechanism for unique or primary key.
--*Action: drop the constraint instead of the index.
===============================================================================
Views in SQL?
- A View in SQL is a virtual table based on the result set of a SELECT query.
- It does not store data physically but acts as a stored query that retrieves data from underlying tables.
Key Features of Views
- Acts as a Virtual Table – Can be used like a table in queries.
- Does Not Store Data – Only stores the SQL query definition.
- Provides Data Abstraction – Users can access only required columns.
- Enhances Security – Restricts access to specific data.
- Simplifies Queries – Can be used to store complex queries for reuse.
CREATE VIEW Empview AS
SELECT emp_id, first_name FROM emp1 WHERE description = 'tester';
select * from Empview;
===============================================================================
How to update exisiting VIEW?
CREATE or REPLACE VIEW Empview_update AS
SELECT emp_id, first_name,last_name FROM emp1 WHERE description = 'tester';
===============================================================================
How to drop ViEW?
drop view Empview_update;
===============================================================================
What are the limitations of views?
- Cannot perform INSERT, UPDATE, or DELETE if it contains JOIN, GROUP BY, DISTINCT, etc.
- Performance may be slower than querying tables directly.
- Materialized views require extra storage and periodic refresh.
===============================================================================
Can We Use Variables in SQL Views?
- No, SQL Views do not support variables directly.
- Views are stored queries that retrieve data from tables, and they cannot have procedural logic like variables, loops, or conditions.
- Use Stored Procedures, Functions, Temporary Tables, or Session Variables as a workaround.
===============================================================================
To check all the views in SQL?
SELECT * FROM ALL_VIEWS where view_name='READONLYVIEW';
SELECT * FROM USER_VIEWS where view_name='READONLYVIEW';
===============================================================================
Types of VIEWS?
------------------------
+++ Simple View
------------------------
- Based on a single table.
- Allows SELECT, INSERT, UPDATE, DELETE (if it includes the primary key).
CREATE VIEW Empview AS SELECT emp_id, first_name FROM emp1 WHERE description = 'tester';
------------------------
+++ Complex View
------------------------
- Based on multiple tables using JOIN, GROUP BY, Aggregations, etc.
- May not always allow INSERT, UPDATE, DELETE.
CREATE VIEW Empview1 AS
select city,first_name, last_name, first_name || '_' || last_name as full_name, sum(salary) as fullsalary from emp1
group by city,first_name,last_name;
CREATE VIEW EmployeeSalary1 AS
SELECT e1.emp_id, e1.first_name, e4.dept_name, e4.salary
FROM emp1 e1
JOIN emp4 e4 ON e1.emp_id = e4.emp_id
JOIN emp2 d ON e1.dept_id = d.DEPARMENT_ID;
------------------------------------------------
+++ Materialized View (Oracle, PostgreSQL, etc.)
------------------------------------------------
- Stores physical data for faster performance.
- Requires manual or automatic refresh.
CREATE MATERIALIZED VIEW EmployeeMV AS SELECT emp_id, last_name, city FROM emp1;
EXEC DBMS_MVIEW.REFRESH('EmployeeMV');
------------------------
+++ Indexed View (SQL Server Only)
------------------------
- A Complex View with an Indexed Column.
- Improves query performance by storing the result.
CREATE VIEW IndexedView WITH SCHEMABINDING AS
SELECT emp_id, COUNT(*) AS Total FROM Employees GROUP BY emp_id;
Create Index:
CREATE UNIQUE CLUSTERED INDEX idx_emp ON IndexedView(emp_id);
------------------------
+++ Updatable View
------------------------
- Supports INSERT, UPDATE, DELETE if it includes a Primary Key.
CREATE VIEW UpdatableView AS SELECT first_name,CITY FROM emp1;
update UpdatableView SET first_name = first_name || '_GN' where city='hyd'; -- Updating record from view table
delete from UpdatableView where first_name='SUKMAR'; -- deleting record from view table
insert into UpdatableView(first_name,city) values('GRITHIK', 'OMAN'); --cannot insert value, bacause primary key can't be null
CREATE VIEW UpdatableView1 AS SELECT emp_id,first_name,CITY FROM emp1;
insert into UpdatableView1(emp_id, first_name,city) values(002,'GRITHIK', 'OMAN'); --Inserted value, bacause primary key included
------------------------
+++ Read-Only View
------------------------
- Does not allow INSERT, UPDATE, DELETE.
- This is particularly useful for scenarios where you want to restrict users from altering the data while still providing them access to view it.
CREATE VIEW ReadOnlyView AS
SELECT emp_id, salary FROM emp1 WITH CHECK OPTION;
===============================================================================
Cumulative Sum in SQL?
Cumulative sum (running total) can be calculated using the SUM() window function with the OVER() clause.
select first_name, emp_id, dept_name,
sum(salary) over (PARTITION by city order by dept_name desc)as Cumulative_Sum from emp1
fetch first 5 rows only;
Explanation:
SUM(Sales_Amount) OVER (...) → Computes a running total.
PARTITION BY Salesperson → Groups cumulative sum per salesperson.
ORDER BY Sale_Date → Ensures the cumulative sum is calculated in chronological order.
===============================================================================
Year-on-Year (YoY) Growth Calculation in SQL ?
Year-on-Year (YoY) growth measures the percentage change in a value (e.g., sales, revenue) compared to the previous year.
YOY growth% = ((current sales - pervious sales) / previous sales)) * 100
SELECT Year, Sales_Amount,
LAG(Sales_Amount) OVER (ORDER BY Year) AS Previous_Year_Sales,
ROUND(((Sales_Amount - LAG(Sales_Amount) OVER (ORDER BY Year))
/ NULLIF(LAG(Sales_Amount) OVER (ORDER BY Year), 0)) * 100, 2) AS YoY_Growth_Percentage
FROM Sales;
Explanation of the Code:
1) SELECT Year, Sales_Amount: This part of the query selects the Year and Sales_Amount columns from the Sales table.
2) LAG(Sales_Amount) OVER (ORDER BY Year) AS Previous_Year_Sales: This line uses the LAG function to retrieve the sales amount from the previous year, ordered by the Year. The result is aliased as Previous_Year_Sales.
3) ROUND(((Sales_Amount - LAG(Sales_Amount) OVER (ORDER BY Year)) / NULLIF(LAG(Sales_Amount) OVER (ORDER BY Year), 0)) * 100, 2) AS YoY_Growth_Percentage:
This complex expression calculates the YoY growth percentage.
It subtracts the previous years sales from the current year's sales, divides the result by the previous year's sales (using NULLIF to avoid division by zero), and multiplies by 100 to convert it into a percentage.
Finally, the ROUND function is applied to limit the result to two decimal places, making it more presentable.
===============================================================================
Types of relationships are commonly defined between tables in a relational database?
One-to-One Relationship:
- In this relationship, each record in one table is related to exactly one record in another table.
- Example: A Person table and a Passport table where each person has only one passport.
One-to-Many Relationship:
- This is the most common type of relationship where a record in one table can be associated with multiple records in another table, but each record in the second table is associated with only one record in the first table.
- Example: A Department table and an Employee table where one department can have multiple employees, but each employee belongs to one department.
Many-to-One Relationship:
- This is the inverse of a one-to-many relationship. A record in the second table is related to one record in the first table, but the first table can have multiple records related to the second table.
- Example: In the Employee table, each employee is associated with one department (many employees belong to one department).
Many-to-Many Relationship:
- In this relationship, multiple records in one table can be associated with multiple records in another table. This is usually achieved by using a junction or associative table.
- Example: A Student table and a Course table where each student can enroll in multiple courses, and each course can have multiple students. A junction table like Student_Course would be used to manage this relationship.
Self-Referencing Relationship:
- A table can have a relationship with itself, where records in the same table are related to each other. This is often used in hierarchical data structures.
- Example: An Employee table where each employee has a Manager (who is also an employee in the same table).
===============================================================================
how to update random dates in newly added date column ?
ALTER TABLE sales ADD creation_dt DATE;
UPDATE sales
SET creation_dt = TO_DATE('2020-01-01', 'YYYY-MM-DD') +
(DBMS_RANDOM.VALUE * (SYSDATE - TO_DATE('2020-01-01', 'YYYY-MM-DD')));
===============================================================================
how to update Random Date Between Two Specific Dates?
UPDATE sales
SET creation_dt = TO_DATE('2022-01-01', 'YYYY-MM-DD') +
(DBMS_RANDOM.VALUE * (TO_DATE('2022-12-31', 'YYYY-MM-DD') - TO_DATE('2022-01-01', 'YYYY-MM-DD')));
===============================================================================
how to Update Random Years ?
UPDATE sales
SET year = TRUNC(2000 + DBMS_RANDOM.VALUE * (2025 - 2000 + 1));
===============================================================================
how to insert Multiple column Random values ?
INSERT INTO sales (year, creation_dt)
SELECT
TRUNC(2000 + DBMS_RANDOM.VALUE * (2005 - 2000 + 1)),
TO_DATE('2022-01-01', 'YYYY-MM-DD') +
(DBMS_RANDOM.VALUE * (TO_DATE('2025-12-31', 'YYYY-MM-DD') - TO_DATE('2022-01-01', 'YYYY-MM-DD')))
FROM sales;
===============================================================================
how to Update Multiple column Random values ?
UPDATE sales
SET year = TRUNC(2000 + DBMS_RANDOM.VALUE * (2025 - 2000 + 1));
update sales
Set
year= TRUNC(2000 + DBMS_RANDOM.VALUE * (2005 - 2000 + 1)),
creation_dt TO_DATE('2022-01-01', 'YYYY-MM-DD') +
(DBMS_RANDOM.VALUE * (TO_DATE('2025-12-31', 'YYYY-MM-DD') - TO_DATE('2022-01-01', 'YYYY-MM-DD')));
===============================================================================
what is retention query sql?
- A retention query in SQL is typically used to identify and remove data that is older than a certain threshold or period, ensuring that only relevant or recent data is retained in the database.
- The exact query will depend on your retention policy (e.g., keeping only records for the past X days).
Key Uses of Retention Queries:
- Delete Old Data: To automatically delete records that are no longer needed, such as log files, transaction records, or old user activity data.
- Archive Old Data: To move old records to an archive table or database for historical reference while removing them from the active system.
- Maintain Data Freshness: To ensure that only the most recent data is retained in the primary tables and older data is either deleted or archived.
- SELECT * FROM sales WHERE creation_dt < ADD_MONTHS(SYSDATE, -12); --Retrive Data Older Than 1 Year
- DELETE FROM sales WHERE creation_dt < ADD_MONTHS(SYSDATE, -12); -- Delete Data Older Than 1 Year
- SELECT * FROM sales WHERE creation_dt >= SYSDATE - 30; -- Retrive with in 30 days
Important Considerations:
- Data Backup: Always back up data before running any deletion or archiving query, especially for critical business data.
- Indexing: Retention queries can be resource-intensive, so ensuring that the date columns (e.g., created_at) are indexed can improve performance.
- Testing: Test retention queries in a staging or development environment to avoid accidentally losing important data in production.
===============================================================================
How many types of clauses in SQL?
SQL clauses are used to filter, manipulate, and retrieve data efficiently. Here are the main types of clauses in SQL:
SELECT Clause : Used to retrieve data from a table.
select emp_id, city from emp1;
FROM Clause : Specifies the table from which to retrieve data.
select emp_id, city from emp1;
WHERE Clause : Filters records based on a condition.
select emp_id, city from emp1 where emp_id <300;
GROUP BY Clause : Groups records with the same values in specified columns.
select emp_id, dept_id,count(*) from emp1 where dept_id=20 group by dept_id,emp_id;
HAVING Clause : Used with GROUP BY to filter grouped data.
select dept_id,city,count(*)from emp1 group by dept_id,city having count(*)>1;
ORDER BY Clause : Sorts the result set in ascending (ASC) or descending (DESC) order.
select dept_id,city,count(*)from emp1 group by dept_id,city having count(*)>1
order by city desc;
LIMIT / FETCH Clause : Limits the number of rows returned.
select dept_id,city,count(*)from emp1 group by dept_id,city having count(*)>1 order by city desc
fetch first 1 row only;
JOIN Clause : Combines records from two or more tables.
select e1.emp_id, e1.dept_id, e2.dept_name, e2.city, e1.salary from emp1 e1
join emp4 e2 on e1.salary=e2.salary;
UNION and UNION ALL Clause : Combines results of two queries (UNION removes duplicates, UNION ALL keeps them).
select * from emp1 union select * from emp4;
select * from emp1 union all select * from emp4;
EXISTS/ NOT EXISTS Clause :
- EXISTS is faster than IN for large datasets.
- It stops execution once it finds a match.
- EXISTS is used with correlated subqueries.
select emp_id, first_name,salary from emp4 e2 where exists (select * from emp1 e1 where e1.salary=e2.salary group by first_name);
select emp_id, first_name,salary from emp4 e2 where not exists (select * from emp1 e1 where e1.salary=e2.salary group by first_name);
IN Clause : Checks if a value exists in a given set.
select emp_id, first_name,salary from emp4 where dept_id in (30,20);
BETWEEN Clause : Filters values within a given range.
select emp_id, first_name,salary from emp4 where salary between 400 and 2000;
LIKE Clause : Searches for a specified pattern in a column.
select emp_id, first_name,salary from emp4 where first_name like 'div%';
CASE Clause : Used for conditional logic inside queries.
select emp_id, first_name,salary, case when city='hyd' then 'HYDERABAD' else 'Not HYDERABAD' end as CITYDETAILS from emp4;
DISTINCT Clause : Returns unique values from a column.
select DISTINCT (CITY) from emp4;
===============================================================================
get number of emp working in each department?
select dept_id, count(*) as dept_count from emp4 group by dept_id;
===============================================================================
third highest salary from each department
select * from (
SELECT dept_id, emp_id, salary, DENSE_RANK() OVER (ORDER BY salary DESC) AS rnk FROM emp4
)ranked
where rnk=3;
10 999 1
10 333 99999.56 2
10 463 23534.56 3 <<-----
10 731 6534.56 4
10 453 2334.56 5
10 111 2334.56 5
20 461 8734.56 1
20 931 534.56 2
20 633 34.56 3 <<-----
select * from (
SELECT dept_id, emp_id, salary, row_number() OVER (ORDER BY salary DESC) AS rnk FROM emp4
)ranked
where rnk=3;
10 999 1
10 333 99999.56 2
10 463 23534.56 3 <<-----
10 731 6534.56 4
10 453 2334.56 5
10 111 2334.56 6
20 461 8734.56 1
20 931 534.56 2
20 633 34.56 3 <<-----
DENSE_RANK() assigns a unique rank for each salary within a department.
PARTITION BY department_id ensures ranking is separate for each department.
We filter for rnk = 3 to get the 3rd highest salary.
ROW_NUMBER() does not assign the same rank for duplicate salaries.
If multiple employees have the same salary, this method may skip some values.
SELECT MAX(salary) AS third_highest_salary
FROM emp4 where salary<
(
SELECT MAX(salary)as second_highest_salary FROM emp4 WHERE salary <
(
SELECT MAX(salary)as first_highest_salary FROM emp4
)
) ;
===============================================================================
write a query if employee
age is less than or equal to 20 then 'Fresher'
age is between 20 to 60 then 'Experienced'
else 'Retired'
ALTER TABLE emp4 ADD age INT;
UPDATE emp4 SET age = TRUNC(DBMS_RANDOM.VALUE(20, 71));
SELECT emp_id, first_name, age,
CASE
WHEN age <= 20 THEN 'Fresher'
WHEN age BETWEEN 20 AND 60 THEN 'Experienced'
ELSE 'Retired'
END AS status
FROM emp4;
===============================================================================
How find a duplicate records from a table?
select first_name, count(*) from emp4 group by first_name having count(*)>1;
===============================================================================
How to select duplicate records from a table?
select a.* from emp4 a
join( select first_name from emp4 group by first_name having count(*)>1) b
on a.first_name=b.first_name;
SELECT * FROM (
SELECT a.*, ROW_NUMBER() OVER (PARTITION BY first_name ORDER BY rowid) AS rn
FROM emp4 a
) subquery
WHERE rn > 1;
select * from emp4 a where rowid>(select min(rowid) from emp4 b where a.first_name= b.first_name);
-- Using a Common Table Expression (CTE) - often clearer
WITH DuplicateFirst_Name AS (
SELECT first_name
FROM emp4
GROUP BY first_name
HAVING COUNT(*) > 1
)
SELECT *
FROM emp4
WHERE first_name IN (SELECT first_name FROM DuplicateFirst_Name);
===============================================================================
How to delete duplicate records from a table?
DELETE FROM emp6
WHERE first_name IN (
SELECT first_name FROM emp6 GROUP BY first_name HAVING COUNT(*) > 1 );
DELETE FROM emp6 a
WHERE rowid > (SELECT MIN(rowid) FROM emp6 b WHERE a.first_name = b.first_name);
DELETE FROM emp6
WHERE rowid NOT IN ( SELECT MIN(rowid) FROM emp6 GROUP BY first_name);
---Keeps only one record per first_name and deletes the rest.Uses MIN(rowid) to retain the earliest inserted record.
===============================================================================
How to select the top five salaries from a table ?
select * from emp6 order by salary desc
fetch first 5 rows only;
SELECT * FROM (
SELECT * FROM emp6 ORDER BY salary DESC
) WHERE ROWNUM <= 5;
SELECT * FROM (
SELECT a.*, ROW_NUMBER() OVER (ORDER BY salary desc) AS rn
FROM emp6 a
) ranked
WHERE rn <=5;
SELECT * FROM (
SELECT a.*, DENSE_RANK() OVER (ORDER BY salary DESC) AS rnk
FROM emp6 a
) salary_rank WHERE rnk <= 5;
===============================================================================
How to select the least five salaries from a table using ROWNUM?
SELECT * FROM (
SELECT a.*, ROW_NUMBER() OVER (ORDER BY salary asc) AS rn
FROM emp6 a
) ranked
WHERE rn <=5;
select * from emp6 order by salary asc
fetch first 5 rows only;
SELECT * FROM (
SELECT a.*, DENSE_RANK() OVER (ORDER BY salary asc) AS rnk
FROM emp6 a
) salary_rank WHERE rnk <= 5;
===============================================================================
Query for the Nth highest salary:
SELECT * FROM (
SELECT emp_id, first_name, salary, DENSE_RANK() OVER (ORDER BY salary DESC) AS rank_num FROM emp6
) ranked
WHERE rank_num = &N;
--It handles duplicate salaries (ties get the same rank).
--531 AKHIL 6534.56 5
--731 MAHESH 6534.56 5
SELECT * FROM (
SELECT emp_id, first_name, salary, row_number() OVER (ORDER BY salary DESC) AS rank_num FROM emp6
) ranked
WHERE rank_num = &N;
--It gives unique ranks (1, 2, 3, etc.), but does not handle ties. -- --
--531 AKHIL 6534.56 5
SELECT MAX(salary)
FROM emp6 a
WHERE &nth = (SELECT COUNT(salary) FROM emp6 b WHERE a.salary < b.salary) order by salary desc;
===============================================================================
Query for the Nth lowest salary:
SELECT * FROM (
SELECT emp_id, first_name, salary,
DENSE_RANK() OVER (ORDER BY salary ASC) AS rank_num
FROM emp6
) ranked
WHERE rank_num = &N;
--531 AKHIL 6534.56 8
--731 MAHESH 6534.56 8
SELECT * FROM (
SELECT emp_id, first_name, salary,
row_number() OVER (ORDER BY salary ASC) AS rank_num
FROM emp6
) ranked
WHERE rank_num = &N;
--531 AKHIL 6534.56 8
===============================================================================
Query for the 5th highest salary:
SELECT * FROM (
SELECT emp_id, first_name, salary, DENSE_RANK() OVER (ORDER BY salary DESC) AS rank_num FROM emp6 ) ranked
WHERE rank_num = 5;
--531 AKHIL 6534.56 5
--731 MAHESH 6534.56 5
SELECT * FROM (
SELECT emp_id, first_name, salary, row_number() OVER (ORDER BY salary DESC) AS rank_num FROM emp6) ranked
WHERE rank_num = 5;
--531 AKHIL 6534.56 5
select max(salary) from emp6 where salary < (
select max(salary) from emp6 where salary < (
select max(salary) from emp6 where salary < (
select max(salary) from emp6 where salary <
(
select max(salary) from emp6
))));
SELECT MAX(salary)
FROM emp6 a
WHERE 4 = (SELECT COUNT(salary) FROM emp6 b WHERE a.salary < b.salary) order by salary desc;
===============================================================================
Query for the 5th lowest salary:
SELECT * FROM (
SELECT emp_id, first_name, salary, DENSE_RANK() OVER (ORDER BY salary asc) AS rank_num FROM emp6 ) ranked
WHERE rank_num = 5;
--234 SUNNY 2344.56 5
SELECT * FROM (
SELECT emp_id, first_name, salary, row_number() OVER (ORDER BY salary asc) AS rank_num FROM emp6) ranked
WHERE rank_num = 5;
--234 SUNNY 2344.56 5
select min(salary) from emp6 where salary >(
select min(salary) from emp6 where salary >(
select min(salary) from emp6 where salary >(
select min(salary) from emp6 where salary >
(
select min(salary) from emp6
))));
SELECT min(salary) FROM emp6 a
WHERE 4 = (SELECT COUNT(salary) FROM emp6 b WHERE a.salary > b.salary) order by salary desc;
SELECT MIN(salary) FROM emp6 a
WHERE 5 = (SELECT COUNT(DISTINCT salary) FROM emp6 b WHERE a.salary >= b.salary);
===============================================================================
display the even rownum employess?
SELECT * FROM (
SELECT a.*, ROW_NUMBER() OVER (ORDER BY emp_id) AS rn FROM emp6 a
) WHERE MOD(rn, 2) = 0;
WITH NumberedRows AS (
SELECT emp_id, first_name, salary, ROW_NUMBER() OVER (ORDER BY emp_id) AS rn FROM emp6
)
SELECT * FROM NumberedRows WHERE MOD(rn, 2) = 0;
===============================================================================
display the odd rownum employess?
SELECT * FROM (
SELECT a.*, ROW_NUMBER() OVER (ORDER BY emp_id) AS rn FROM emp6 a
) WHERE MOD(rn, 2) != 0;
WITH NumberedRows AS (
SELECT emp_id, first_name, salary, ROW_NUMBER() OVER (ORDER BY emp_id) AS rn FROM emp6
)
SELECT * FROM NumberedRows WHERE MOD(rn, 2) != 0;
===============================================================================
Department wise highest salary?
select dept_id, max(salary)as high_sal from emp6 group by dept_id;
SELECT dept_id, emp_id, first_name, salary FROM (
SELECT dept_id, emp_id, first_name, salary, RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS rnk FROM emp6
) WHERE rnk = 1;
10 333 divya 99999.56 1
10 463 divya 23534.56 2
10 999 SUKMAR 10001.23 3
10 731 MAHESH 6534.56 4
10 543 ALBERT 4544.12 5
10 234 SUNNY 2344.56 6
10 453 DIVYA 2334.56 7
10 111 DIVYA 2334.56 7
10 123 PRABHU 22.23 8
SELECT dept_id, emp_id, first_name, salary FROM (
SELECT dept_id, emp_id, first_name, salary, dense_RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS rnk FROM emp6
) WHERE rnk = 1;
10 333 divya 99999.56 1
10 463 divya 23534.56 2
10 999 SUKMAR 10001.23 3
10 731 MAHESH 6534.56 4
10 543 ALBERT 4544.12 5
10 234 SUNNY 2344.56 6
10 453 DIVYA 2334.56 7
10 111 DIVYA 2334.56 7
10 123 PRABHU 22.23 9
Why RANK()? In case multiple employees have the same highest salary, it returns all of them.
DENSE_RANK() does NOT skip ranks.
===============================================================================
First_name=AYYAPPA
last_name=NANDAN
need output like AYYAPPA(N)
select SUBSTR(last_name, 1, 1) from emp6; -- N
select SUBSTR(last_name, 1, 2) from emp6; -- NA
select SUBSTR(last_name, 2, 5) from emp6; -- ANDAN
select '(' || SUBSTR(last_name, 1, 1) || ')' from emp6; --(N)
SELECT first_name || '(' || SUBSTR(last_name, 1, 1) || ')' AS Output
FROM emp6;
--AYYAPPA(N)
--SANDEEP(G)
===============================================================================
Display empoyess from emp group by year wise?
select emp_id, to_char(EMP_JOININGDATE, 'YYYY') as year_wise from emp6 group by emp_id, to_char(EMP_JOININGDATE, 'YYYY')
order by to_char(EMP_JOININGDATE, 'YYYY');
234 2001
===============================================================================
Display empoyess from emp group by month wise?
select emp_id, to_char(EMP_JOININGDATE, 'MM') as year_wise from emp6 group by emp_id, to_char(EMP_JOININGDATE, 'MM')
order by to_char(EMP_JOININGDATE, 'MM');
131 05
select emp_id, to_char(EMP_JOININGDATE, 'MM') as year_wise from emp6 group by emp_id, to_char(EMP_JOININGDATE, 'MM')
order by to_char(EMP_JOININGDATE, 'MM');
131 MAY
===============================================================================
How to find top n records from table?
select * from emp6 fetch first 5 row only;
select * from(select rownum r,e.* from emp6 e) where r<=&n;
SELECT * FROM (
SELECT * FROM emp6 ORDER BY salary ASC
) WHERE ROWNUM <= &N;
SELECT * FROM emp6 ORDER BY salary ASC FETCH FIRST &N ROWS ONLY;
select count(*)-&n+1 from emp6; ----14
select * from(select rownum r,e.* from emp6 e) where r>=(select count(*)-&n+1 from emp6);
===============================================================================
Correlated Subquery in SQL ?
- A correlated subquery is a subquery that depends on the outer query for its values. It executes once for each row processed by the outer query.
- A correlated subquery is a query where the inner query depends on the outer query for its values. The inner query is executed once for each row processed by the outer query, making both queries interdependent.
++++ Below are the Correlated subquery examples
Find Employees Who Earn More Than the Average Salary of Their Department ?
SELECT emp_id, first_name, salary, dept_id from emp6 e1
where salary > (
SELECT AVG(salary)
FROM emp6 e2
WHERE e1.dept_id = e2.dept_id);
Retrieve Employees With the Highest Salary in Their Department?
SELECT emp_id, first_name, salary, dept_id from emp6 e1
where salary = (
SELECT MAX(salary)
FROM emp6 e2
WHERE e1.dept_id = e2.dept_id);
Find employees Who worked More Than 5 dept_name ?
SELECT emp_id, first_name, last_name , dept_name
FROM emp6 e1
WHERE 5 < (
SELECT COUNT(*)
FROM emp6 e2
WHERE e1.dept_name = e2.dept_name
);
===============================================================================
Key Differences HAVING & GROUP BY :
Find departments where the average salary is greater than 50,000 ?
select emp_id, dept_name,avg(salary) from emp6
group by emp_id, dept_name
having avg(salary)>5000;
Find the total salary per department ?
select sum(salary), dept_name from emp6
group by dept_name;
===============================================================================
SUBSTR Function in SQL ?
- The SUBSTR (or SUBSTRING in some databases) function is used to extract a substring from a given string.
- SUBSTR(string, start_position, length)
Extract first 3 letters from first_name?
select first_name, substr(first_name, 1, 3) from emp6;
DIVYA DIV
PRABHU PRA
SUNNY SUN
Extract last 4 letters from dept_name?
select dept_name, substr(dept_name, -4, 4) from emp6;
programmar mmar
tester ster
developer oper
===============================================================================
INSTR Function in SQL ?
- The INSTR function is used to find the position of a substring within a string. If the substring is found, it returns the position (index) of its first occurrence. If not found, it returns 0.
- INSTR(string, substring, start_position, occurrence)
- string → The main string in which to search.
- substring → The substring to find.
- start_position (Optional, Default = 1) → The position from where to start searching.
- occurrence (Optional, Default = 1) → Specifies which occurrence to find (1st, 2nd, etc.).
find position of the letter 'SPACE' ?
select instr('gopinath reddy',' ',1,1) from dual; ---- 9
find position of the letter 'e' ?
select instr('gopinath reddy','e',1,1) from dual; ---- 11
find 2nd occurence of the letter 'y' ?
select instr('sunny bunny munny','y',1,2) from dual; --- 11
find the postion of the string 'sql' ?
select instr('learning sql','sql',1,1) from dual; --- 10
find the last occourance of the letter in a string ?
select dept_name, instr(dept_name,'m',-1, 1) from emp6; or
select dept_name, instr(dept_name,'m',-1) from emp6;
programmar 8
progammar 7
select substr('gopinath reddy',instr('gopinath reddy',' ',1,1)) from dual; --- reddy
===============================================================================
query extracts the username part (before @) from an email column in the emp6 table.?
SELECT SUBSTR(email, 1, (INSTR(email, '@', 1, 1)) - 1) FROM emp6;
divyarani@123.com divyarani
mhtprabhu@123.com mhtprabhu
hariprabhu@123.com hariprabhu
--SUBSTR(email, 1, (INSTR(email, '@', 1, 1)) - 1)
--Extracts the substring from position 1 up to (position of '@' - 1), which gives the username before @.
===============================================================================
LAPD & RPAD
select * from emp6;
LPAD(string, length, pad_character)
select first_name, LPAD(first_name, 10, 'S') from emp6;
DIVYA SSSSSDIVYA
PRABHU SSSSPRABHU
select first_name, RPAD(first_name, 10, 'S') from emp6;
DIVYA DIVYASSSSS
PRABHU PRABHUSSSS
SELECT RPAD(first_name, 10, ' ') as rpad1, RPAD(last_name, 10, ' ') as rpad2,RPAD(first_name, 10, ' ') || RPAD(last_name, 10, ' ') as align_rpad FROM emp6;
RPAD1 RPAD2 ALIGN_RPAD
DIVYA RANI DIVYA RANI
PRABHU TARAK PRABHU TARAK
===============================================================================